Unser Widget kann ganz einfach und wartungsfrei auf
einer beliebigen Artikelseite eingebunden werden.
Nutzer verbringen durch das Anhören von Artikeln mehr Zeit auf Ihrer Webseite, weshalb sich Faktoren wie Kundenbindung, Werberelevanz und positive SEO-Einflüsse verbessern können.
Um jedem Hörertyp gerecht zu werden, bieten wir die Audioversionen der Artikel in verschiedenen Wiedergabegeschwindigkeiten an.
Bei Bedarf kann der Lectorem-Player an die Farben und das Design Ihrer Webseite angepasst werden.
Maschinelle Text-to-Speech-Sprachsynthese ist nichts Neues. Allerdings war die Qualität der Sprachroboter lange Zeit nicht annähernd mit der eines menschlichen Sprechers vergleichbar. Mit Aufkommen des Trends der persönlichen Assistenten wie Alexa von Amazon, Siri von Apple oder Google Home wurde zunehmend Forschungsarbeit in die Verbesserung der Sprachqualität investiert. Hierbei ist insbesondere die Arbeit von DeepMind hervorzuheben.
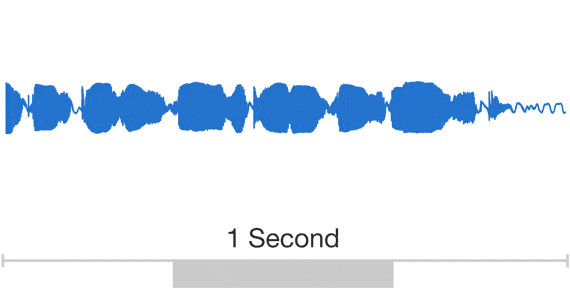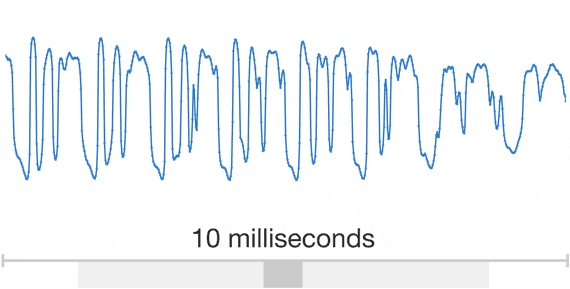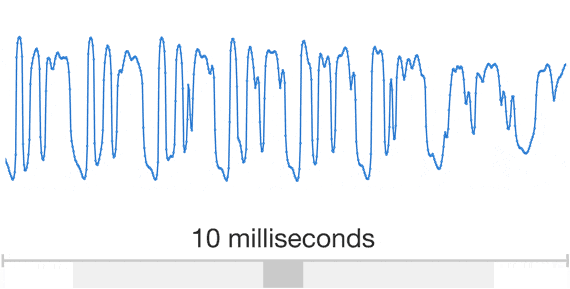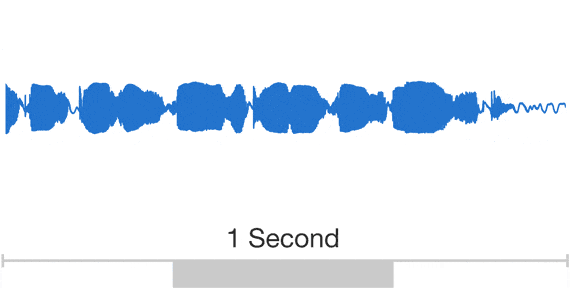
DeepMind hat bahnbrechende Forschungsarbeit zu Modellen für maschinelles Lernen geleistet, um Sprache zu erzeugen, die menschliche Stimmen nachahmt und natürlicher klingt. Schall und somit auch Sprache sind zeitlich präzise aufeinander abgestimmte Druckvariationen, die vom Ohr aufgenommen und im Gehirn verarbeitet werden. Zeichnet man die Druckvariationen über die Zeit auf erhält man Wellenformen (wie rechts dargestellt). DeepMinds Ansatz besteht darin, die menschliche Sprache auf Basis der Schalldruckwellenformen mit neuronalen Netzen nachzubilden. Durch diese Forschung wird die Lücke zur menschlichen Leistung um mehr als 70 % reduziert. Google stellt mit WaveNet die Implementation von DeepMinds Forschung zur Verfügung.
Fortlaufende Verbesserung der Betonung, Aussprache und Interpretation verschiendster Interpunktionsmöglichkeiten, insbesondere im Bezug auf die Eigenheiten der deutschen Sprache.
Die einfachste Möglichkeit, Lectorem auf Ihrer Webseite zu integrieren, ist die Nutzung eines "Embedded Snippets", eines auf der Artikelseite eingefügten Code-Schnipsels. Die Integration auf Kundenseite dauert damit nur wenige Minuten.
Eine weitere Methode wäre die manuelle Erstellung der Audio-Datei und der Einfügung eines statischen Code-Blocks, was jedoch zusätzlichen Aufwand bei jedem geschriebenen Artikel, auch rückwirkend für ältere Artikel, bedeutet.
Selbstverständlich können die Farben des Lectorem-Players an Ihr Corporate Design frei nach Wunsch angepasst werden.
Sie hören: Die Technologie hinter Lectorem - Lectorem.de
Maschinelle Text-to-Speech-Sprachsynthese ist nichts Neues. Allerdings war die Qualität der Sprachroboter lange Zeit nicht annähernd mit der eines menschlichen Sprechers vergleichbar. Mit Aufkommen des Trends der persönlichen Assistenten wie Alexa von Amazon, Siri von Apple oder Google Home wurde zunehmend Forschungsarbeit in die Verbesserung der Sprachqualität investiert. Hierbei ist insbesondere die Arbeit von DeepMind hervorzuheben.
DeepMind hat bahnbrechende Forschungsarbeit zu Modellen für maschinelles Lernen geleistet, um Sprache zu erzeugen, die menschliche Stimmen nachahmt und natürlicher klingt. Schall und somit auch Sprache sind zeitlich präzise aufeinander abgestimmte Druckvariationen, die vom Ohr aufgenommen und im Gehirn verarbeitet werden. Zeichnet man die Druckvariationen über die Zeit auf erhält man Wellenformen (wie rechts dargestellt). DeepMinds Ansatz besteht darin, die menschliche Sprache auf Basis der Schalldruckwellenformen mit neuronalen Netzen nachzubilden. Durch diese Forschung wird die Lücke zur menschlichen Leistung um mehr als 70 % reduziert. Google stellt mit WaveNet die Implementation von DeepMinds Forschung zur Verfügung.
Fortlaufende Verbesserung der Betonung, Aussprache und Interpretation verschiendster Interpunktionsmöglichkeiten, insbesondere im Bezug auf die Eigenheiten der deutschen Sprache.